Bioinformatics is defined as the application of tools of computation and analysis to the capture and interpretation of biological data. It is an interdisciplinary field, which harnesses computer science, mathematics, physics, and biology. Fig.1.1. is showing the bioinformatics, medicine and science.
fig.1.1Interactions of disciplines that have contributed to the formation of bioinformatics.
The above picture is showing the complete details of of Bioinformatics that upon which factors or components it came into being.
Let's discuss its components in detail;
Biology
Biology is basically the study of life, the study of living organisms and their interactions with non-living things to survive in the environment. As, there is genes and genomes involved in living organisms body, so to study those genes and genomes bioinformatics is necessary. that is why Biology is the essential component of Bioinformatics.
2. Medicine
Bioinformatics is used in personalized medicine to analyze data from genome sequencing or microarray gene expression analysis in search of mutations or gene variants that could affect a patient's response to a particular drug or modify the disease prognosis.
3. Mathematics/ Physics
Bioinformatics uses the methods of Applied Mathematics, Statistics and Informatics. Research in computational biology often intersects with systems biology. visit this link to understand how mathematics involves in Bioinformatics biotecharticles.com
Now, question arises here that Is physics required for bioinformatics? Bioinformatics is an amorphous discipline that could be described as “biologically inspired computer science.” Butbioinformatics also draws ideas from physics, chemistry, biochemistry, mathematics, and statistics. visit this site to know more about how physics is involved in Bioinformaticshttps://physicstoday.scitation.org.
4. Computer Sciences
Bioinformatics is the application of computer technology to the management of biological information. One of the major activities that the field of bioinformatics involves is the development of software tools that helps students of Engineering Colleges in India generate useful knowledge within the biological field. visit this link for more; aryacollege.in
History of Emergence and Development
Bioinformatics term was coined by Paulien Hogeweg and Ben Hesper in 1970. Its meaning was very different from current description and referred to the study of information processes in biotic systems like biochemistry and biophysics. However, the emergence of bioinformatics tracks back to the 1960s. It was appeared in concordance with the development of protein sequencing methods from a variety of organisms and with the availability of protein sequences after Frederick Sanger determined the sequence of insulin in the early 1950s. New computer methods to analyze and compare a large number of protein sequences of different organisms were needed because handling many amino acid sequences manually was impractical. This led in compiling the first “Protein Information Resources” (PIR) by Margaret Oakley Dayhoff and her collaborators at the National Biomedical Research Foundation. Dayhoff's team successfully organized the protein sequences into distinct groups and sub-groups based on sequence similarity and percent accepted mutation (PAM) matrices. This was published as protein sequences atlas that has been widely used in performing protein sequence alignments and database similarity searches. This was pioneered methods of protein sequence alignment and molecular evolution. In the 1970s, Elvin A. Kabat further contributed to bioinformatics development by his extended protein sequence analysis of comprehensive volumes of antibody sequences, released in collaboration with Tai Te Wu between 1980 and 1991.
With the objective of providing the theoretical background to immunology experiments in 1974, George Bell and colleagues initiated the collection of DNA sequences into GenBank. During 1982–1992, the first version of GenBank was prepared by Walter Goad's group and the efforts resulted in the development of presently known and widely used DNA sequence databases of GenBank, “The European Molecular Biology Laboratory (EMBL) , and DNA DataBank of Japan (DDBJ)in 1979, 1980, and 1984, respectively. Most important development in DNA sequence databases, however, was incorporation of web-based searching algorithms allowing researchers to find and compare the target DNA sequences. Such first developments and resulting computer software called “GENEINFO” and its derivative version of “Entrez” were developed by David Benson and David Lipman and colleagues. This software allowed researchers to rapidly search database-indexed sequences and match them with queried sequence. Software became readily available through web-based interface of the National Center of Biotechnology Information (NCBI) database. Molecular sequence analysis, comparison, and visualization methods have been improved, and many different methodologies have been contributed to bioinformatics advancements in this direction. Such advancements can be exemplified by the development of dot matrix and diagram methods, alignment of sequences by dynamic programming, finding of local alignments between sequences, multiple sequence alignment tools, predicting the secondary structures of RNAs, determination of evolutionary relationships of sequences , and assigning the gene function based on sequence similarity of known function from models . Development of FASTA , BLAST, and their various modifications has further powered the bioinformatics field and greatly improved the biological data analysis. In addition, rapid genome-wide gene expression profiling and analysis opportunities , biological pathway assignment and identification, data storing, and mining and querying for large volume of biological datasets have further provided unprecedented popularity of bioinformatics in the scene of world science, which has been briefly reviewed below.
fig.1.2. Dynamics of bioinformatics-related publications over the past four decades.
Databases in Bioinformatics
An organized collection of data is referred to as database that aims to collect schemes, tables, queries, reports, images, and other objects. An access to information in the databases is provided by an integrated set of computer software, which is referred to as a “database management system” (DBMS). The DBMS allows users to access all of the data contained in the databases. It has general functions for data definition, entry, storage, update, administration, and retrieval of large quantities of information in an organized way that requires modeling (hierarchical and network models), clustering, query languages and query optimization, and visualization algorithms.
Development of databases, therefore, is significantly dependent on bioinformatics tools, advances, research, and applications. There is a large number of different types of databases available, which cover all aspects of biological data storage and organization. Some aforementioned databases such as GenBank, EMBL, DDJB belong to primary nucleotide sequence databases. There are meta-databases that incorporate data compiled from multiple other databases such as Entrez, mGen, Metascape, etc. Some others are specialized databases such as those specific to an organism, for example, TAIR, the p53 Knowledgebase (p53), the plant alternative splicing database (PASD); the plant secretome, and subcellular proteome knowledgebase (PlantSecKB. All databases vary in their data definition, usage, format, and access types. In this book, the chapter by Kadam et al. specifically describes databases and bioinformatics algorithms related to allergen informatics, discussing the concepts of allergen bioinformatics and the key areas for potential development in the allergology, whereas Bell and Kramvis highlight public sequence database for Hepatitis B virus. In this book, readers can find a comprehensive discussion for bioinformatics resources, including databases for plant “omics,” written by Rahman et al.
Scope of Bioinformatics
Bioinformatics is used in every field of life such as Clinical practices, personalized medicine, agriculture, and forensic science all have a high demand for bioinformaticians. Bioinformatics has many uses in the bioenergy, veterinary research, and biotechnology manufacturing sectors.
Bioinformatics graduates are sought by a variety of pharmaceutical firms, healthcare organizations, environmental biotech companies, and educational institutions.
Trends in Bioinformatics Bioinformatics is a rapidly evolving field that combines computer science, statistics, and biology to extract knowledge and insights from large biological datasets. In recent years, there have been several notable trends in the field of bioinformatics that are worth highlighting. In this article, we will discuss some of the most significant trends in bioinformatics. Artificial Intelligence and Machine Learning One of the most significant trends in bioinformatics is the increased use of artificial intelligence (AI) and machine learning (ML) in the analysis of biological data. AI and ML algorithms can be trained to recognize patterns in large datasets, which can help identify potential targets for drug discovery or disease diagnosis. For example, deep learning algorithms have been used to analyze gene expression data to identify genes that may be involved in the progression of cancer. Artificial Intelligence (AI) has become an essential tool in the field of ...
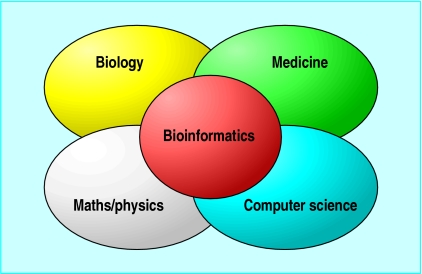 fig.1.1 Interactions of disciplines that have contributed to the formation of bioinformatics.
fig.1.1 Interactions of disciplines that have contributed to the formation of bioinformatics. fig.1.2. Dynamics of bioinformatics-related publications over the past four decades.
fig.1.2. Dynamics of bioinformatics-related publications over the past four decades. 
Comments
Post a Comment